
In the previous post we saw differences, advantages and disadvantages of by-value classes and by-reference classes. As seen in the post, in G-code classes are natively by-value. Meanwhile by-reference classes require the implementation of specific mechanisms or data structures. In this post and in the next one, we will have an overview regarding the main techniques that can be used to obtain a by-reference class. Thus, in the first post we will see mechanisms external to the class in order to use it by-reference. In the second post, on the other hand, we will see mechanisms inside the class to turn it into a “intrinsic” by-reference class.
1. Variables
The simplest and most straightforward way to achieve a by-reference class is to use variables (local or global). In short, we take an object and create a variable to access it for reading and writing. In this way, the object is free from the carrying wire and becomes a by-reference object.
The use of variables can cause race conditions and therefore their use is not recommended. This does not mean that variables should never be used. Sometimes variables are useful to keep the code clean and to avoid overcomplex sharing mechanisms that, in some cases, may be unnecessary.
For example, variables are fine when used with a Write Once Read Many (WORM) approach. In this case, the variable is written only once, after which each subsequent access is read. In this scenario, no race condition is present.
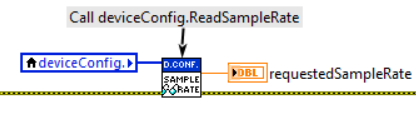
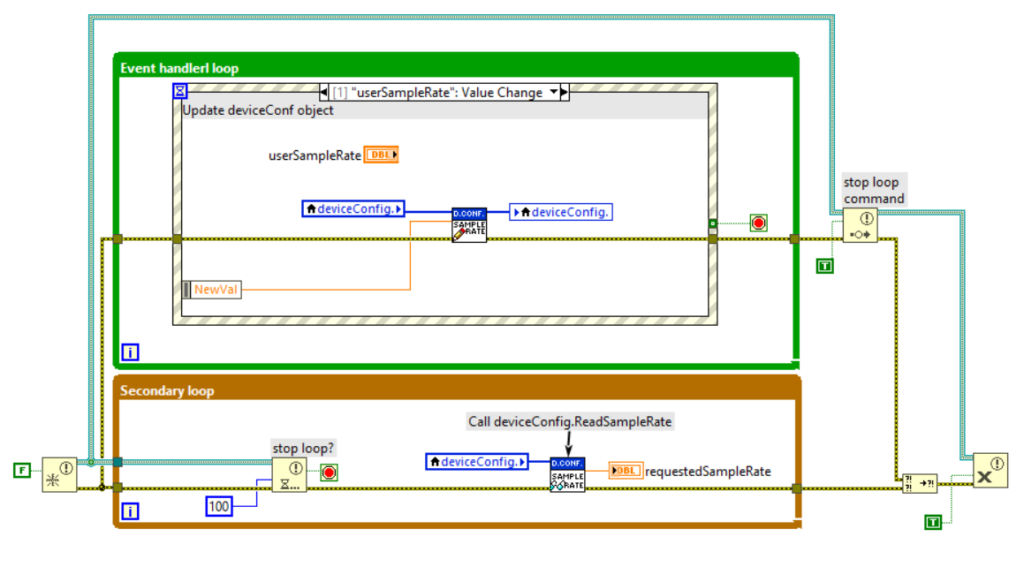
2. Functional Global Variable (FGV)
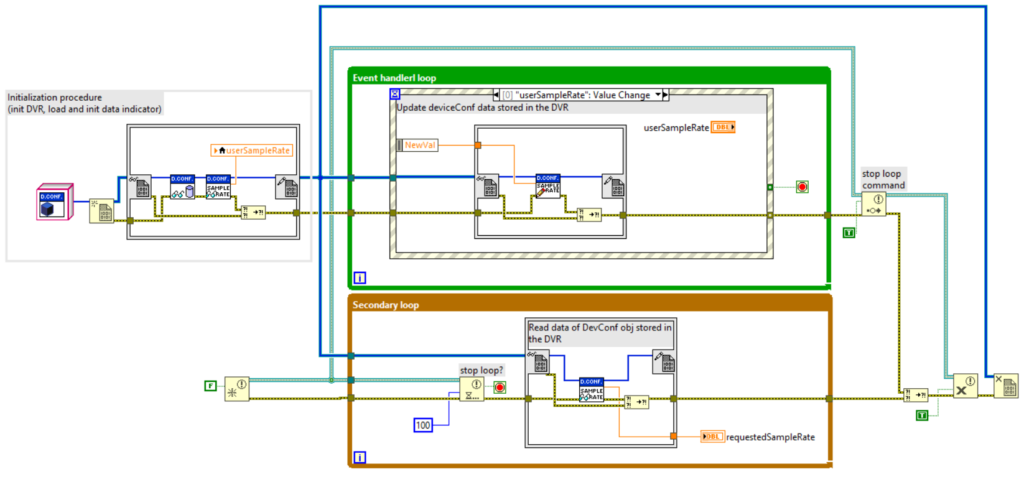
An FGV is a nonreentrant VI that exploits uninitialized shift-registers to store any type of data (including objects then). The purpose of an FGV is to store data between consecutive calls of the FGV itself. In its simplest form, an FGV stores data. However, it is more effective to use it to encapsulate more complex operations than simply write and read-data.
An FGV is typically accompanied by an input (enum or string) that indicates the operation to be performed. To explore this topic further, here are a couple of useful links: What is a Functional Global Variable? and Functional Global Variable (FGV).
Let us return to OOP programming. It is possible to store an object within an FGV so that the object itself is by-reference. By encapsulating an object in an FGV, the object is stored in memory (i.e., in the VI that implements the FGV itself) and becomes, precisely, a by-reference object.
To avoid race conditions, it is useful to use the FGV not only to store the object but also to delegate specific operations to it, i.e., to directly call methods of the class within the FGV itself. Let’s think about a class that implements a simple counter. The state of the class is a number that represents the current value of the count. In addition, the class has the method Increment which increments the current value of the counter (the class state). If we use an FGV that simply stores the object, in order to call the Increment method, we would have to read the stored value in the FGV, call the Increment method, and then update the value in the FGV. However, this approach generates race conditions. To avoid this, additional logic should be inserted into the FGV by delegating the execution of the Increment method to it. In this case, operations on the object are performed inside the FGV thus protecting us from race condition.
With the use of FGVs, the object becomes a shared resource whose access is mediated by the FGV itself. Moreover, the FGV, being a nonreentrant VI, provides a protection mechanism that guarantees one access at a time. In detail, if two portions of parallel code attempt to access the FGV (and thus the contained object) simultaneously, while one request is fulfilled, the other one awaits completion before being served in turn.
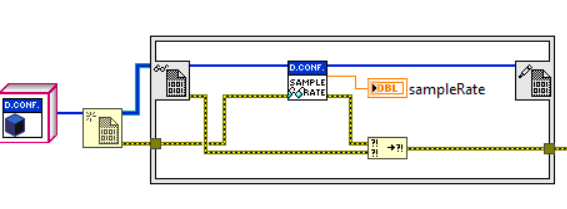
The following figures show an example of an FGV that encapsulates the DeviceConfiguration object. The FGV in the example encapsulates the methods of initializing, loading, and reading/writing the SampleRate property of the DeviceConfiguration object.
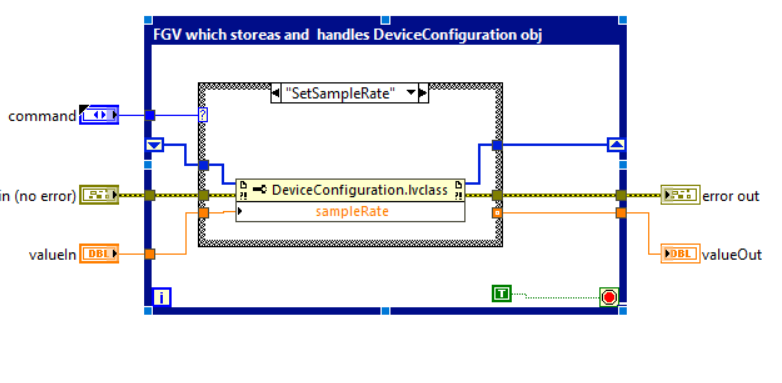
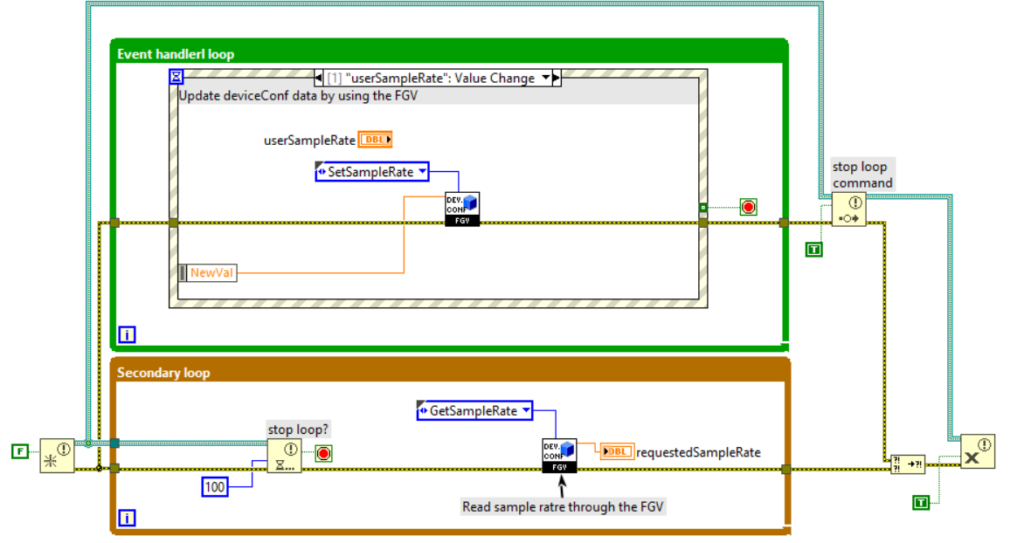
Unlike variables, FGVs, if well implemented, protect us from race conditions. In contrast, the use of FGVs has the following disadvantages:
- Limited scalability. If we have to add new public methods to the object stored by the FGV, we need to modify the code of the FGV itself. Now, if we also have to use several classes by-reference, it is necessary to provide an FGV (thus a dedicated VI with related code) for each of them and this can be troublesome.
- A jumble of terminals in the FGV connector pane. The FGV can encapsulate numerous methods of the object it stores, which may require inputs and outputs of different types. These inputs and outputs must be exposed in the interface that the object has with the outside world and must then be reported in the connector pane of the FGV. This can make the connector pane confusing, with numerous inputs and outputs, making the FGV difficult to be used.
3. Data Value Reference (DVR)
A DVR is a shared memory location. The wire carrying a DVR carries the memory reference to the data, not the data itself. The DVR requires the use of an In Place structure for reading and writing access, preventing the creation of memory copies of the data it carries. DVR is automatically locked to other writers while a process writes to it and have the option to allow multiple parallel reads.
Making a by-reference object through the use of a DVR is very simple. You simply create a DVR of the class type you want to make by-reference. Once that is done, you access the object through the In Place structure.
Using DVRs to make a class by-reference has the following advantages:.
- Protection mechanisms. The DVR provides protection mechanisms for concurrent access to the data (in our case to the object) that guarantee exclusive access to each “writer.” In detail, if two portions of parallel code simultaneously attempt to gain write access to the DVR (and thus to the contained object), while one request is fulfilled, the other one awaits completion before being served in turn.
- Full scalability. DVRs are created at run-time and in a vey simple way. Apart from the amount of memory occupied, there is no limit to the number of DVRs we can create.
- Improved efficiency in memory management. Accessing the data in a DVR requires the use of the In Place structure, which avoids the creation of memory copies of the data it carries.
- Excellent integration between DVRs and objects. Using a dedicated DVR to carry an object of a class allows access to the property nodes of that class without using the in-place structure. This is a facilitator provided by NI to make the code cleaner. In practice, the access to the DVR is the same as if we were using the classical approach.

- Established technology. DVRs have been present and used for several years and can therefore be considered a reliable tool.
The only drawback when using DVRs is the use of the In Place structure with its odd error handling that makes the code look unsightly.
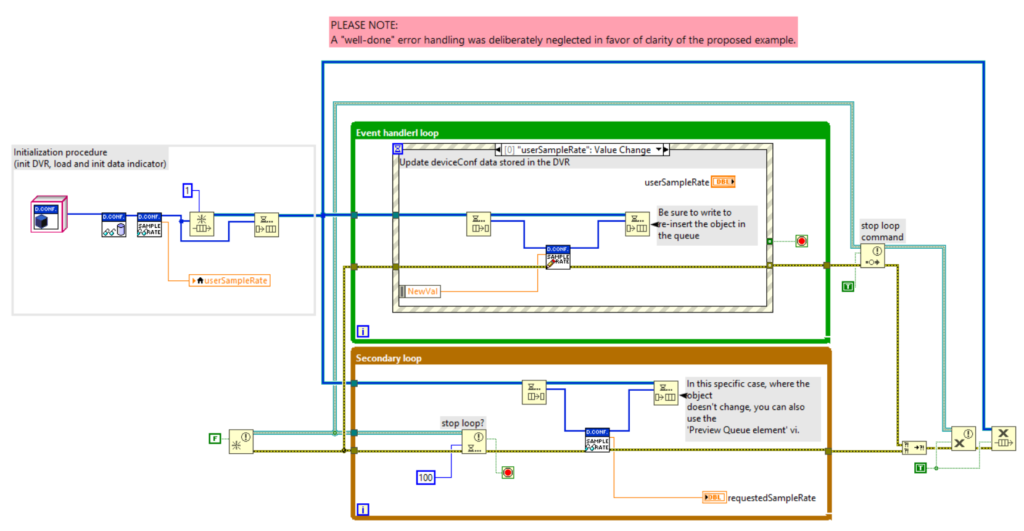
4. Single Element Queue (SEQ)
A SEQ is a queue forced to have one and only one element. We can therefore see the queue reference as the reference to the data it contains. The SEQ exploits the lock (Dequeue) and unlock (Enqueue) functions of queues to guarantee exclusive access to the data.
Functionally, a SEQ is similar to a DVR. However, since the advent of DVRs, given their more efficient memory management and excellent integration with classes, the trend is to prefer DVRs to have a pointer to a memory area.
As with DVRs, rendering a by-reference object through the use of a SEQ is very simple. You simply place the object you want to make by-reference in a queue of length 1. Once done, you access the object through the Dequeue and and Enqueue functions (next figures).
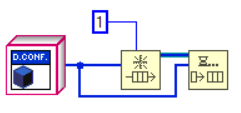
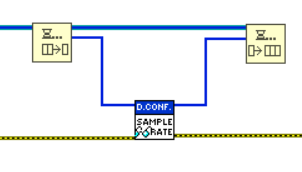
Some notes on the examples in the figure above:
- The queue must be forced to have 1 element.
- In data extraction (Dequeue) the timeout must be -1. This causes any other concurrent operations to wait for the current operation to be completed.
- The error wire is intentionally not connected to the Dequeue function. A more effective error handling can certainly be thought of, but it is essential that the re-entry of the data into the queue is always guaranteed.
Using SEQs to make a class by-reference has the following advantages:
- Protection mechanisms. SEQ provides protection mechanisms for concurrent access to the data (in our case to the object) that guarantee restricted access to each “writer.” In detail, if two portions of parallel code simultaneously attempt to gain write access to the queue (and thus to the contained object), while one request is fulfilled, the other awaits completion before it can be served in turn.
- Full scalability. SEQs are created at run-time and in a straightforward manner. Other than the amount of memory occupied, there is no limit to the number of SEQs we can create.
- Ability to retrieve the queue by name. Since it is a queue, a SEQ reference can also be created by name. This allows the queue reference to be created anywhere in the code, without having to carry around the relative wire. We can consider this an advantage because it allows the SEQ to be easily called at different points in the code. At the same time, it must be said that this can make it more difficult to figure out where an object is modified, making any debugging more complex.
The main disadvantage of SEQ is that it requires precautions to ensure its operation (timeout to -1, error handling, sequential dequeue and enqueue) which are entirely under the responsibility of the developer. Failure to do so has serious negative impacts on the entire application. If you dequeue the queue but not the subsequent enqueue, access to the SEQ is locked irretrievably.
Conclusions (part 1)
In this post we have seen various implementation techniques for using a class in by-reference mode. The techniques presented in the post (variables, FGV, DVR, and SEQ) are all mechanisms external to the class. With these approaches, the class remains by-value. It is the code external to the class that allows it to be used by-reference.
In the next post we will look at techniques which are internal to the class to turn it into a by-reference class.
The methods seen are adapted to different situations and contexts. Variables are definitely the fastest to use (fast in code implementation) but at the same time they give race conditions. Variables are fine with WORM approaches.
FGVs replace variables because they avoid race conditions and can also be used to encapsulate logic. Remember that FGVs are VIs that must therefore be created at edit-time, thus making them nonscalable.
Finally, DVRs and SEQs are excellent tools for achieving a by-reference object. They are both easy to use, have excellent scalability, and, under the functionality point of view, they are equivalent tools. Given the more efficient memory management and excellent integration with classes, DVRs are to be preferred.

