
Nel precedente post abbiamo visto differenze, vantaggi e svantaggi di classi by-value e classi by-reference. Come visto, in LabVIEW le classi sono nativamente by-value, mentre le classi by-reference richiedono l’implementazione di meccanismi o di strutture dato specifiche per poterle ottenere. In questo post e nel prossimo faremo una panoramica riguardo le principali tecniche che possono essere usate per ottenere una classe by-reference. Nel primo post vedremo così dei meccanismi esterni alla classe per poterla utilizzare by-reference. Nel secondo post vedremo invece dei meccanismi interni alla classe per trasformarla in una classe by-reference “intrinseca”.
1. Variabili
Il metodo più semplice e immediato per ottenere una classe by-reference è utilizzare le variabili (locali o globali). In breve, prendiamo un oggetto e ne creiamo una variabile per accedervi in lettura e scrittura. In questo modo, l’oggetto si svincola dal filo che lo trasporta e diventa un oggetto by-reference.
L’utilizzo di variabili può causare race condition e quindi ne è sconsigliato l’utilizzo. Ciò non vuol dire che le variabili non debbano mai essere usate. A volte le variabili sono utili per mantenere il codice pulito e per evitare meccanismi di condivisione troppo articolati che, in alcuni casi, possono essere non necessari.
Le variabili vanno per esempio bene se utilizzate con un approccio Write Once Read Many (WORM – scrivi una volta, leggi molte volte). In questo caso, la variabile è scritta solo una volta, dopodiché ogni successivo accesso è in lettura. In questo scenario, non è presente race condition.
2. Functional Global Variable (FGV)
Una FGV è un VI non rientrante che sfrutta shift-register non inizializzati per storicizzare dati di qualsiasi tipo (anche oggetti quindi). Lo scopo di una FGV è quello di conservare i dati tra chiamate consecutive della FGV stessa. Nella sua forma più semplice, una FGV storicizza il dato. È tuttavia più efficace utilizzarla per incapsulare operazioni più complesse rispetto al semplice scrivi-dato e leggi-dato.
Una FGV è tipicamente accompagnata da un ingresso (enum o stringa) che indica l’operazione da eseguire. Per approfondire l’argomento, ecco un paio di link utili: What is a Functional Global Variable? e Functional Global Variable (FGV).
Torniamo alla programmazione OOP. È possibile memorizzare un oggetto all’interno di una FGV così da rendere l’oggetto stesso by-reference. Incapsulando un oggetto in una FGV, l’oggetto è memorizzato in memoria (cioè nel VI che implementa la FGV stessa) e diventa, appunto, un oggetto by-reference.
Per evitare race condition, è utile utilizzare la FGV non solo per memorizzare l’oggetto ma anche per delegarne operazioni specifiche, cioè chiamare direttamente i metodi della classe all’interno della FGV stessa. Pensiamo ad una classe che implementa un semplice contatore. Lo stato della classe è un numero che rappresenta il valore attuale del conteggio. La classe, inoltre, ha il metodo Increment che incrementa il valore attuale del contatore (lo stato della classe). Se utilizziamo una FGV che semplicemente memorizza l’oggetto, per poter chiamare il metodo Increment, dovremo leggere il valore storicizzato nella FGV, chiamare il metodo Increment e poi aggiornare il valore nella FGV. Questo approccio però genera race condition. Per evitare ciò, è opportuno inserire della logica nella FGV delegandole l’esecuzione del metodo Increment. In questo caso, le operazioni sull’oggetto sono eseguite all’interno della FGV proteggendoci quindi da race condition.
Con utilizzo delle FGV, l’oggetto diventa una risorsa condivisa il cui accesso è mediato dalla FGV stessa. La FGV, inoltre, essendo un VI non rientrante, fornisce un meccanismo di protezione che garantisce un accesso alla volta. Nel dettaglio, se due porzioni di codice parallelo tentano di accedere simultaneamente alla FGV (e quindi all’oggetto contenuto), mentre una delle due richieste è soddisfatta, l’altra ne attende il completamento prima di poter essere servita a sua volta.
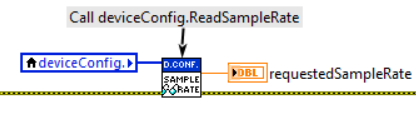
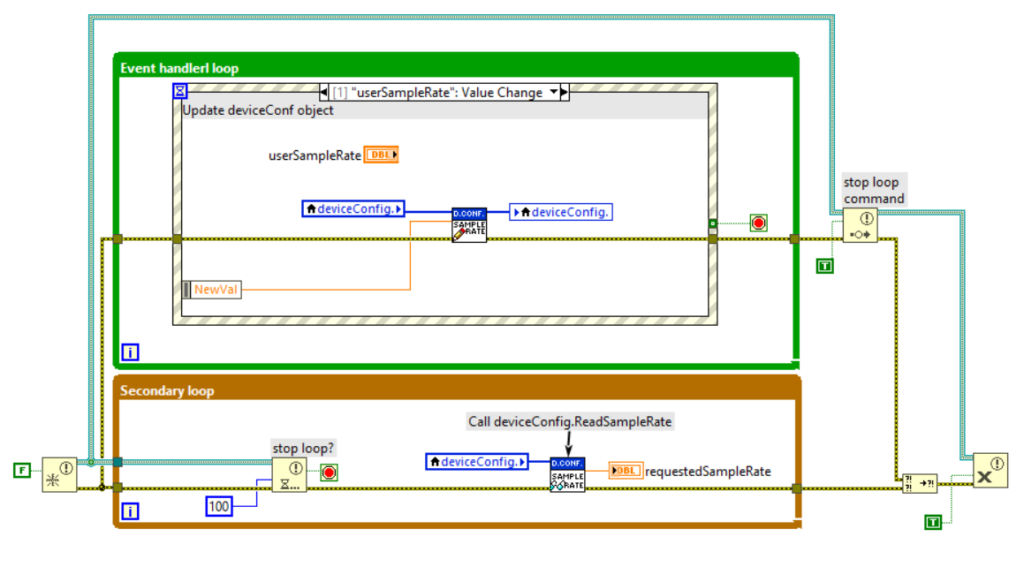
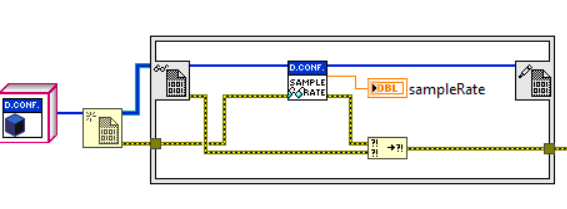
Le figure seguenti mostrano un esempio di FGV che incapsula l’oggetto DeviceConfiguration. La FGV nell’esempio prevede la chiamata dei metodi di inizializzazione, caricamento e la lettura/scrittura della proprietà SampleRate dell’oggetto DeviceConfiguration.
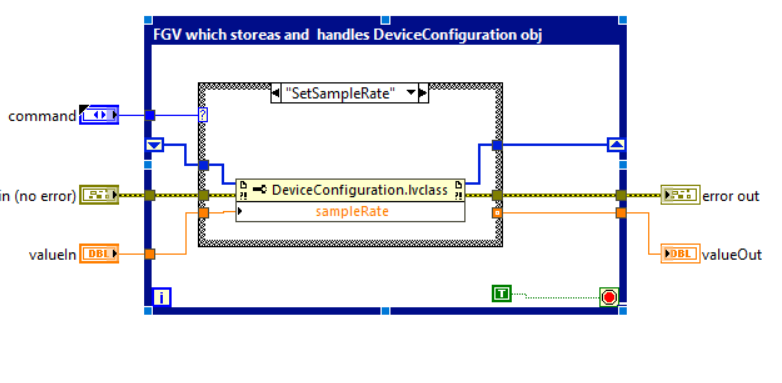
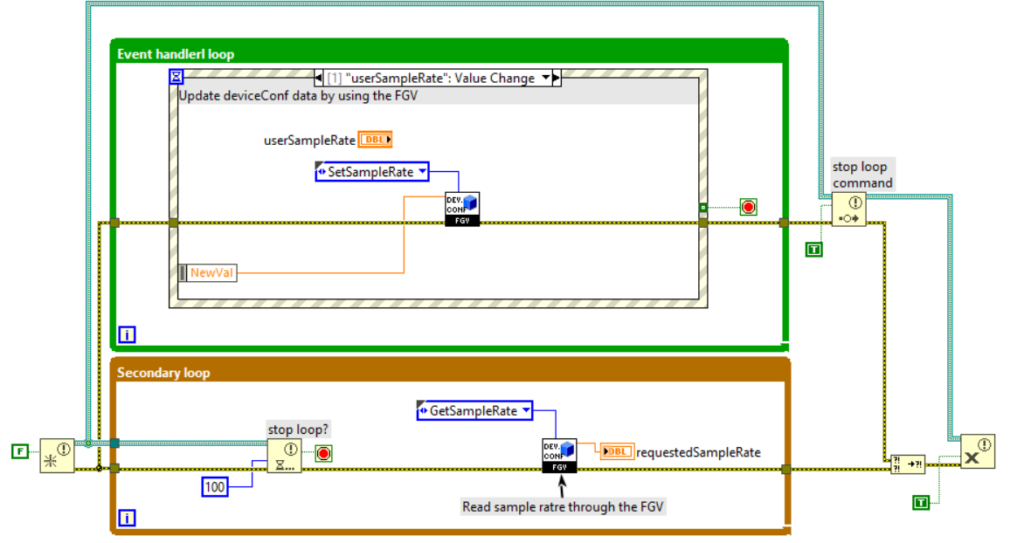
A differenza delle variabili, le FGV, se ben realizzate, ci proteggono da race condition. Di contro, l’utilizzo di FGV presenta i seguenti svantaggi:
- Scalabilità limitata. Pensiamo di aggiungere nuovi metodi pubblici alla classe contenuta nella FGV. Per ogni metodo aggiunto, è necessario modificare il codice della FGV. Pensiamo inoltre di voler rendere by-reference diverse classi. È necessario prevedere una FGV (quindi un VI dedicato con relativo codice) per ognuna di essa e ciò può essere limitante.
- Accozzaglia di terminali nel connector pane della FGV. La FGV può incapsulare numerosi metodi dell’oggetto che storicizza, i quali possono richiedere input e output di tipo diverso. Tali ingressi e uscite devono essere esposti nell’interfaccia che l’oggetto ha con il mondo esterno e devono essere quindi riportati nel connector pane della FGV che contiene l’oggetto. Ciò può rendere il connector pane confuso, con numerosi ingressi e uscite, rendendo la FGV difficile da utilizzare da parte dello sviluppatore.
3. Data Value Reference (DVR)
Un DVR è una posizione di memoria condivisa. Il filo che trasporta un DVR trasporta il riferimento al dato e non il dato stesso. ll DVR richiede l’utilizzo di una struttura In Place per l’accesso in lettura e scrittura, impedendo la creazione di copie in memoria del dato che trasporta. Il DVR è automaticamente bloccato ad altri scrittori mentre un processo scrive su di esso e ha l’opzione che permette più letture parallele.
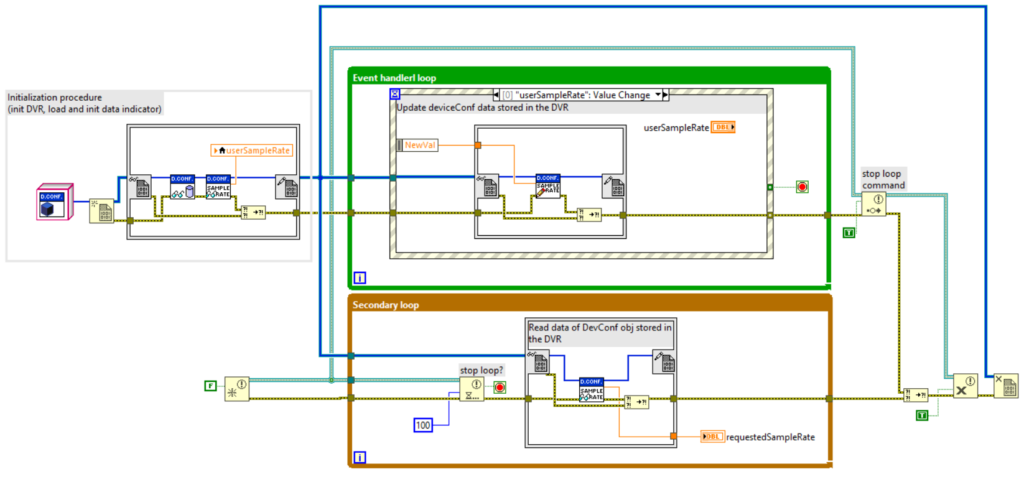
Rendere un oggetto by-reference tramite l’uso di un DVR è molto semplice. È sufficiente creare un DVR del tipo della classe che si vuole rendere by-reference. Una volta fatto, si accede all’oggetto tramite la struttura In Place.
L’utilizzo dei DVR per rendere una classe by-reference ha i seguenti vantaggi:
- Meccanismi di protezione. Il DVR prevede dei meccanismi di protezione per l’accesso concorrente al dato (nel nostro caso all’oggetto) che garantiscono l’accesso riservato ad ogni “scrittore”. Nel dettaglio, se due porzioni di codice parallelo tentano di accedere in scrittura simultaneamente al DVR (e quindi all’oggetto contenuto), mentre una delle due richieste è soddisfatta, l’altra ne attende il completamento prima di poter essere servita a sua volta.
- Completa scalabilità. I DVR sono creati a run-time e in modo semplice e immediato. Oltre alla quantità di memoria occupata, non ci sono limiti al numero di DVR che possiamo creare.
- Migliore efficienza nella gestione della memoria. L’accesso al dato in un DVR richiede l’uso della struttura In Place che evita la creazione di copie in memoria del dato che trasporta.
- Ottima integrazione tra DVR e oggetti. Utilizzare un DVR dedicato per trasportare un oggetto di una classe permette di accedere ai property node della classe stessa senza utilizzare la struttura in place. Si tratta di un facilitatore messo a disposizione da NI per rendere il codice più snello. Nella pratica, l’accesso al DVR avviene esattamente come se utilizzassimo l’approccio classico.

- Tecnologia consolidata. I DVR sono presenti e usati da diversi anni e può quindi essere considerato uno strumento affidabile.
L’unico svantaggio che mi sento di attribuire all’uso del DVR è l’uso della struttura In Place con la sua “esotica” gestione degli errori che rende il codice antiestetico.
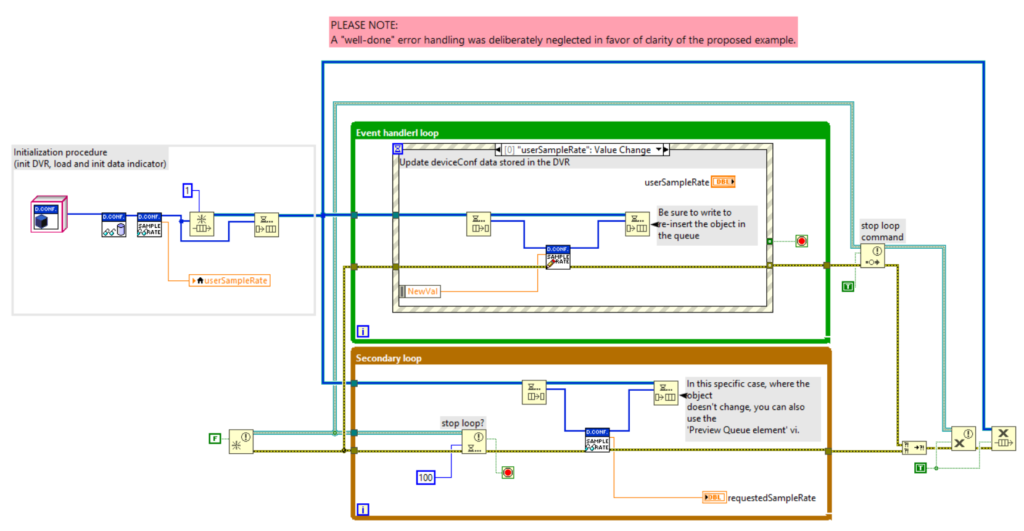
4. Single Element Queue (SEQ)
Un SEQ è una coda forzata ad avere uno e un solo elemento. Possiamo quindi vedere il reference della coda come il riferimento al dato che essa contiene. La SEQ sfrutta le funzioni di lock (Dequeue) e unlock (Enqueue) delle code per garantire l’accesso esclusivo al dato.
Dal punto di vista funzionale, una SEQ è simile ad un DVR. Tuttavia, dall’avvento dei DVR, vista la loro più efficiente gestione della memoria e l’ottima integrazione con le classi, la tendenza è quella di preferire i DVR per avere un puntatore ad un’area di memoria.
Come per i DVR, rendere un oggetto by-reference tramite l’uso di un SEQ è molto semplice. È sufficiente inserire l’oggetto che si vuole rendere by-reference in una coda di lunghezza 1. Una volta fatto, si accede all’oggetto tramite le funzioni Dequeue e e Enqueue (figure successive).
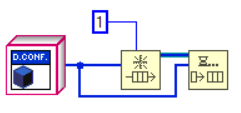
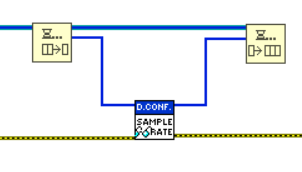
Alcune note sugli esempi in figura sopra:
- La coda deve essere forzata ad avere 1 elemento.
- Nell’estrazione del dato (Dequeue) il timeout deve essere -1. Questo fa sì che eventuali altre operazioni concorrenti di accesso al dato attendano il completamento dell’operazione corrente.
- Il filo dell’errore non è volutamente collegato alla funzione di Dequeue. Si possono sicuramente pensare a gestioni dell’errore più efficaci ma è fondamentale che sia sempre garantito il reinserimento del dato nella coda.
L’utilizzo dei SEQ per rendere una classe by-reference ha i seguenti vantaggi:
- Meccanismi di protezione. Il SEQ prevede dei meccanismi di protezione per l’accesso concorrente al dato (nel nostro caso all’oggetto) che garantiscono l’accesso riservato ad ogni “scrittore”. Nel dettaglio, se due porzioni di codice parallelo tentano di accedere in scrittura simultaneamente alla coda (e quindi all’oggetto contenuto), mentre una delle due richieste è soddisfatta, l’altra ne attende il completamento prima di poter essere servita a sua volta.
- Completa scalabilità. I SEQ sono creati a run-time e in modo semplice e immediato. Oltre alla quantità di memoria occupata, non ci sono limiti al numero di SEQ che possiamo creare.
- Possibilità di richiamare la coda per nome. Trattandosi di una coda a tutti gli effetti, il reference di un SEQ può essere creato anche per nome. Ciò permette di creare il riferimento alla coda in qualsiasi punto del codice, senza dover portarsi in giro il relativo filo. Possiamo considerare questa funzionalità un vantaggio perché rende il SEQ molto comodo da richiamare in diversi punti del codice. Allo stesso tempo, va detto che questo può rendere più difficile capire dove un oggetto è modificato, rendendo quindi più complesso l’eventuale debug.
Il principale svantaggio del SEQ è che richiede alcune accortezze per garantirne il funzionamento (timeout a -1, la gestione degli errori, il dequeue ed enqueue sequenziale) che sono tutte a carico dello sviluppatore. Il mancato rispetto di ciò impatta in maniera grave su tutta l’applicazione. Basti pensare che se si esegue il dequeue della coda ma non il successivo enqueue, l’accesso al SEQ è bloccato irrimediabilmente.
Conclusioni (parte 1)
In questo post abbiamo visto varie tecniche implementative per utilizzare una classe in modalità by-reference. Le tecniche viste (variabili, FGV, DVR e SEQ) sono tutti meccanismi esterni alla classe. Con questi approcci, la classe rimane by-value. È il codice esterno alla classe che permette di utilizzarla by-reference.
Nel prossimo post vedremo invece delle tecniche interne alla classe per trasformarla in una classe by-reference.
I metodi visti si adattano a situazioni e contesti differenti. Le variabili sono sicuramente le più veloci da utilizzare (veloci nell’implementazione del codice) ma allo stesso tempo danno race condition. Le variabili vanno bene con approcci WORM.
Le FGV sostituiscono le variabili perché permettono di evitare race condition e possono anche essere usate per incapsularci della logica. Ricordiamo che le FGV sono dei VI a tutti gli effetti che vanno pertanto create ad edit-time, rendendole quindi non scalabili.
I DVR e i SEQ, infine, sono ottimi strumenti per ottenere un oggetto by-reference. Sono entrambi semplici da usare, hanno un’ottima scalabilità e, dal punto di vista funzionale, sono strumenti equivalenti. Visti la più efficiente gestione della memoria e l’ottima integrazione con le classi, i DVR sono da preferire.

