
I principi SOLID sono 5 linee guida da seguire nella progettazione del software orientato agli oggetti. Essi non sono altro che delle best practice che ci permettono di creare software più gestibili, comprensibili e flessibili. Grazie ai principi SOLID, man mano che le nostre applicazioni crescono di dimensioni, possiamo tenerne sotto controllo la complessità e risparmiarci un sacco di grattacapi.
Vediamo questi principi nel dettaglio.
La parola SOLID è un acronimo il cui significato è:
- S: Single responsibility principle (principio di singola responsabilità).
- O: Open-closed principle (principio aperto/chiuso).
- L: Liskov substition principle (principio di sostituzione di Liskov).
- I: Interface segregation principle (principio di segregazione delle interfacce).
- D: Dependency inversion principle (principio di inversione delle interfacce).
S – Principio di singola responsabilità
Il principio di singola responsabilità (single responsibility principle) afferma che ogni classe dovrebbe avere una e una sola responsabilità, interamente incapsulata al suo interno. In altre parole, ogni classe dovrebbe avere una e una sola funzione e per questo motivo dovrebbe avere un solo motivo per cambiare.
Per esempio, prendiamo la classe Book che modellizza un libro. Sotto riporto sia una versione in C# sia in LabVIEW.
public class Book
{
public string Title { get; set; }
public string Author { get; set; }
public int Pages { get; set; }
// Contructors
}
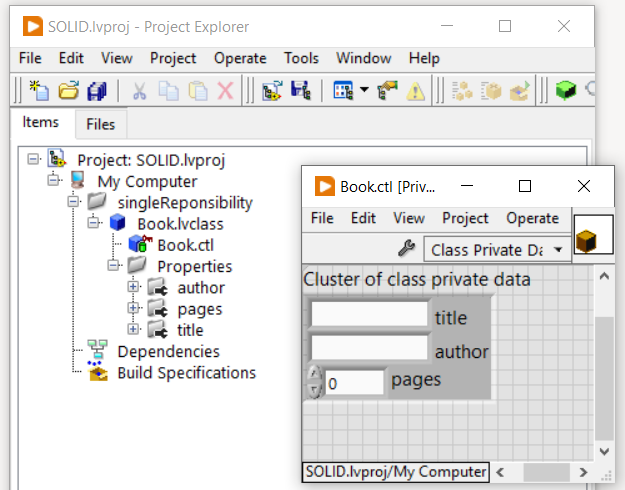
Ora, immaginiamo di dover visualizzare le informazioni del libro (su console per la versione C# e con un Message Box per la versione LabVIEW). Aggiungiamo quindi il metodo ShowInfo alla classe Book. Otteniamo questo:
public class Book
{
public string Title { get; set; }
public string Author { get; set; }
public int Pages { get; set; }
public Book(string title, string author, int pages)
{
this.Title = title;
this.Author = author;
this.Pages = pages;
}
public void PrintInfo()
{
Console.WriteLine($"{ this.Title }, {this.Author}");
}
}
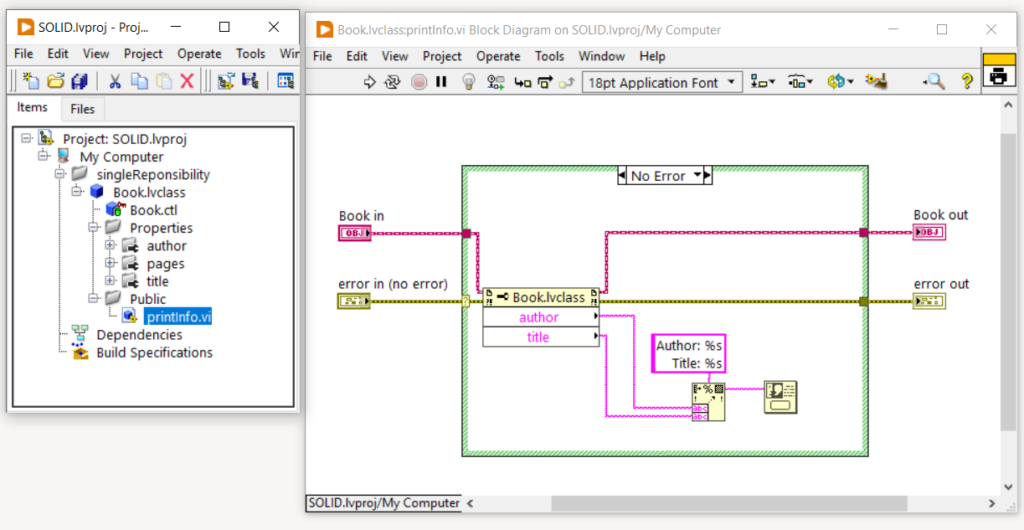
Questo approccio tuttavia rompe il principio di singola responsabilità. La classe Book infatti ora ha due funzionalità/responsabilità: modellizzare l’entità libro e visualizzare a video le informazioni. Se ci soffermiamo a pensare alle possibili evoluzioni di questa semplice classe, ci accorgeremo che ci sono due motivi per modificarla:
- Il cambio del data model, se cambiano cioè i dati modellizzati dalla classe Book. Pensiamo per esempio di dover aggiungere altri attributi come il codice ISBN e la data di pubblicazione.
- Il cambio delle modalità di output per i dati del libro, per esempio se è necessario aggiungere nuove modalità di output o modificare quelle esistenti.
Per tornare a rispettare il principio di singola responsabilità, dovremmo implementare una classe separata che si occupa solo dell’output dei dati libro. Aggiungiamo quindi la classe BookPrinter:
public class BookPrinter
{
public void ShowInfoInConsole(Book book)
{
Console.WriteLine($"{book.Title}, {book.Author}");
}
public void ShowInfoInAnotherWay(Book book)
{
// Another way to output book info
}
}
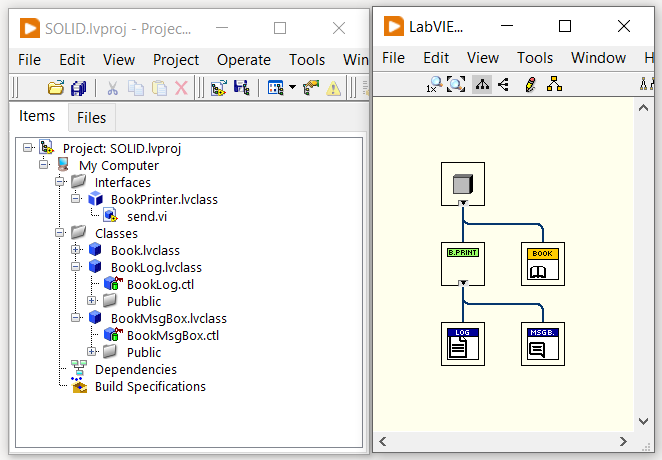
In questo modo, non solo abbiamo sviluppato una classe che solleva il libro dai suoi doveri di gestione dell’output, ma possiamo anche sfruttare la classe BookPrinter per inviare le informazioni libro ad altri output come file, e-mail o altro.
Il rispetto del principio di singola responsabilità apporta i seguenti benefici:
- Si ha un minore accoppiamento. Una classe con una sola funzionalità consente di avere meno dipendenze.
- Classi piccole e ben organizzate rendono il codice più facilmente manutenibile.
- Le classi sono più facili da estendere con nuove funzionalità perché il codice non correlato non è presente nella stessa classe.
- Le dipendenze tra le classi sono più facilmente gestibili perché il codice è meglio raggruppato.
- Le classi sono più piccole migliorando così la leggibilità del codice.
- Il debug è più semplice perché con classi piccole e compatte è più facile identificare bug nel codice.
- L’onboarding di un nuovo membro del team è più semplice poiché il codice è ben organizzato e di facile comprensione.
O – Principio aperto/chiuso
Il principio aperto/chiuso (open/close principle) afferma che le classi dovrebbero essere aperte alle estensioni, ma chiuse alle modifiche. Modifica significa cambiare il codice di una classe esistente ed estensione significa aggiungerne nuove funzionalità. Non modificare codice esistente evita la potenziale introduzione di nuovi bug. Naturalmente, l’unica eccezione alla regola è quando si correggono bug nel codice esistente.
Quindi, secondo quanto affermato da questo principio, dovremmo essere in grado di aggiungere nuove funzionalità senza toccare il codice esistente per la classe. Questo perché ogni volta che modifichiamo il codice esistente, corriamo il rischio di creare potenziali bug. Dovremmo quindi, se possibile, evitare di toccare il codice già testato e in uso.
Ma come aggiungeremo nuove funzionalità senza toccare la classe? Di solito con l’aiuto di interfacce e classi astratte.
Torniamo all’esempio precedente. La classe BookPrinter non rispetta il principio di aperto/chiuso. Questo perché, se volessimo modificare le modalità con cui inviare in output i dati della classe Book, dovremmo mettere mano alla classe BookPrinter stessa. Questa è la classe BookPrinter così come l’abbiamo lasciata:
public class BookPrinter
{
public void ShowInfoInConsole(Book book)
{
Console.WriteLine($"{book.Title}, {book.Author}");
}
public void ShowInfoInAnotherWay(Book book)
{
// Another way to output book info
}
}
Come fare refactoring della classe BookPrinter per soddisfare anche il principio di aperto/chiuso? Possiamo rendere la classe BookPrinter un’interfaccia e poi creare una classe che gestisce l’output in console e che soddisfi la nuova interfaccia BookPrinter.
La nuova interfaccia BookPrinter definisce il metodo Send usato per mandare in output i dati libro. In aggiunta, abbiamo la nuova classe BookConsole (BookMsgBox per l’esempio LabVIEW) che soddisfa l’interfaccia BookPrinter. Ecco il codice:
public interface BookPrinter
{
public void Send(Book book);
}
public class BookConsole : BookPrinter
{
public void Send(Book book)
{
Console.WriteLine($"{book.Title}, {book.Author}");
}
}
Se in futuro nascesse l’esigenza di scrivere i dati libro su un file di testo, le classi esistenti non verranno modificate, ma si creerà una nuova classe BookLog anche questa che soddisfa l’interfaccia BookPrinter:
public class BookLog : BookPrinter
{
public void Send(Book book)
{
// Log book data on text file
}
}
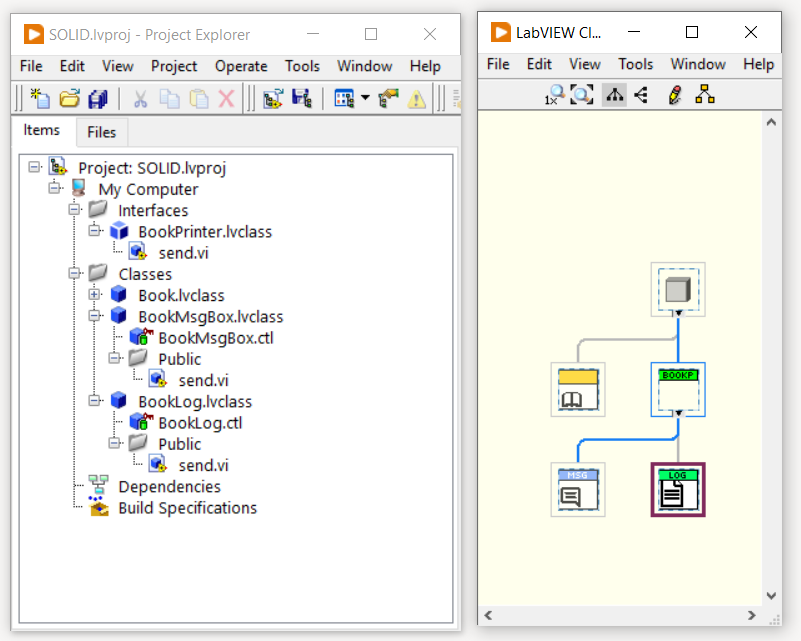
L’utilizzo dell’interfaccia BookPrinter permette quindi di estendere il software con nuove funzionalità senza modificare le classi e le entità esistenti. In parole povere, il programma non dipende dall classe concreta ma dall’interfaccia BookPrinter. In questo modo, è possibile modificare il comportamento del software aggiungendo classi che soddisfino la suddetta interfaccia. L’operazione di istanziare la classe concreta può essere fatta tramite un meccanismo di dependency injection.
L – Principio di sostituzione di Liskov
Il principio di sostituzione di Liskov (Liskov substition principle) afferma che gli oggetti dovrebbero poter essere sostituiti con dei loro sottotipi, senza alterare il comportamento del programma che li utilizza. Ciò significa che, dato che la classe B è una sottoclasse della classe A, dovremmo essere in grado di passare un oggetto di classe B a qualsiasi metodo che si aspetta un oggetto di classe A e il metodo non dovrebbe dare alcun output strano in quel caso.
Questo è il comportamento previsto, perché quando usiamo l’ereditarietà assumiamo che la classe figlia erediti tutto ciò che ha la superclasse. La classe figlia estende il comportamento ma non lo restringe mai. Pertanto quando una classe non obbedisce a questo principi, questo porta a bug difficili da rilevare.
Vediamo un esempio. Abbiamo una classe base Bird e la classe figlia Mockingbird. La classe Mockingbird sovrascrive il metodo Fly:
public class Bird
{
public virtual void Fly() { }
}
public class Mockingbird : Bird
{
public override void Fly()
{
Console.WriteLine("I'm flying!");
}
}
Ma cosa succederebbe se avessimo anche la classe Kiwi (che non vola)?:
public class Kiwi : Bird
{
public override void Fly()
{
throw new Exception("I cannot fly");
}
}
Ciò viola il principio di sostituzione di Liskov perché utilizzare la classe Kiwi all’interno del programma potrebbe creare malfunzionamenti e comportamenti inattesi.
Nel nostro caso, un possibile approccio per rispettare il principio di Liskov è inserire la classe intermedia FlyingBirds:
public class Bird { }
public class FlyingBird : Bird
{
public virtual void Fly() { }
}
public class Mockingbird : FlyingBird
{
public override void Fly()
{
Console.WriteLine("I'm flying!");
}
}
public class Kiwi : Bird { }
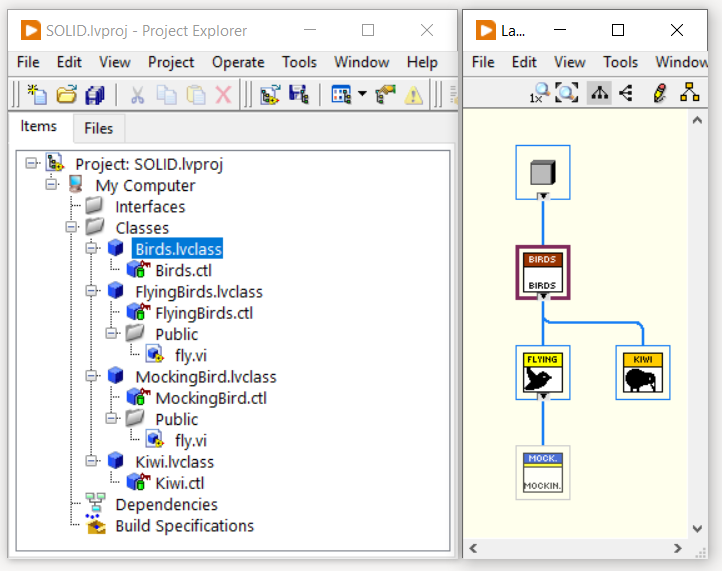
Con questa nuova architettura, se il programma client utilizza un’istanza della classe Bird, non può utilizzare il metodo Fly(). In questo caso passando la classe MockingBird o Kiwi non si creano comportamenti inattesi. Se invece il programma client utilizza l’oggetto FlyingBirds, anche se gli viene passato l’oggetto MockingBird, il programma dovrebbe funzionare allo stesso modo. In questo caso, inoltre non è possibile passare l’oggetto Kiwi perché non è una sottoclasse di FlyingBirds.
I – Principio di segregazione delle interfacce
Il principio di segregazione delle interfacce (interface segregation principle) afferma che molte interfacce specifiche sono migliori di un’interfaccia generica. Secondo questo principio, le classi non dovrebbero essere costrette a implementare una funzione di cui non hanno bisogno. Una classe non dovrebbe quindi dipendere da metodi che non usa. È quindi preferibile che le interfacce siano numerose, specifiche e piccole (composte da pochi metodi) piuttosto che poche, generali e grandi. Questo approccio consente a ciascuna classe di dipendere da un insieme minimo di metodi, ovvero quelli appartenenti alle interfacce che effettivamente usa. Secondo questo principio, un oggetto dovrebbe tipicamente implementare numerose interfacce, una per ciascun ruolo che l’oggetto stesso gioca in diversi contesti o in diverse interazioni con altri oggetti.
Supponiamo di implementare un servizio di ordinazioni dove il cliente può ordinare la prima portata, la seconda portata ed il dessert. Decidiamo quindi di mettere tutti i metodi per le ordinazioni nell’unica interfaccia OrderService:
public interface OrderService
{
public void OrderStarter(string order);
public void OrderSecondCourse(string order);
public void OrderDessert(string order);
}
Supponiamo ora di avere una promozione speciale per l’ordinazione della sola prima portata. Creiamo quindi la classe StarterOnlyService:
public class StarterOnlyService : OrderService
{
public void OrderStarter(string order)
{
Console.WriteLine($"Received order of started: { order }");
}
public void OrderSecondCourse(string order)
{
throw new Exception("No second course in StarterOnlyService");
}
public void OrderDessert(string order)
{
throw new Exception("No dessert in StarterOnlyService");
}
}
La classe StarterOnlyService supporta solo l’ordine della prima portata ma, implementando l’interfaccia OrderService, siamo costretti ad implementare anche i restanti metodi (che generano un’eccezione). Pare piuttosto ovvio che questa soluzione violi il principio di segregazione delle interfacce.
Possiamo quindi fare refactoring del nostro sistema di ordinazione, implementando un’interfaccia specifica per ogni modalità di ordinazione:
public interface OrderStarter
{
public void OrderStarter(string order);
}
public interface OrderSecondCourse
{
public void OrderSecondCourse(string order);
}
public interface OrderDessert
{
public void OrderDessert(string order);
}
La classe StarterOnlyService implementerà solo le interfacce che davvero deve implementare. In questo caso la sola interfaccia OrderStarter:
public class StarterOnlyService : OrderStarter
{
public void OrderStarter(string order)
{
Console.WriteLine($"Received order of started: { order }");
}
}
Nel caso in cui, invece, dovessimo gestire l’ordinazione completa, avremo una seconda classe che implementerà tutte le tre interfacce:
public class OrderFull : OrderStarter, OrderSecondCourse, OrderDessert
{
public void OrderDessert(string order)
{
Console.WriteLine($"Received order of dessert: {order}");
}
public void OrderSecondCourse(string order)
{
Console.WriteLine($"Received order of second course: {order}");
}
public void OrderStarter(string order)
{
Console.WriteLine($"Received order of started: {order}");
}
}
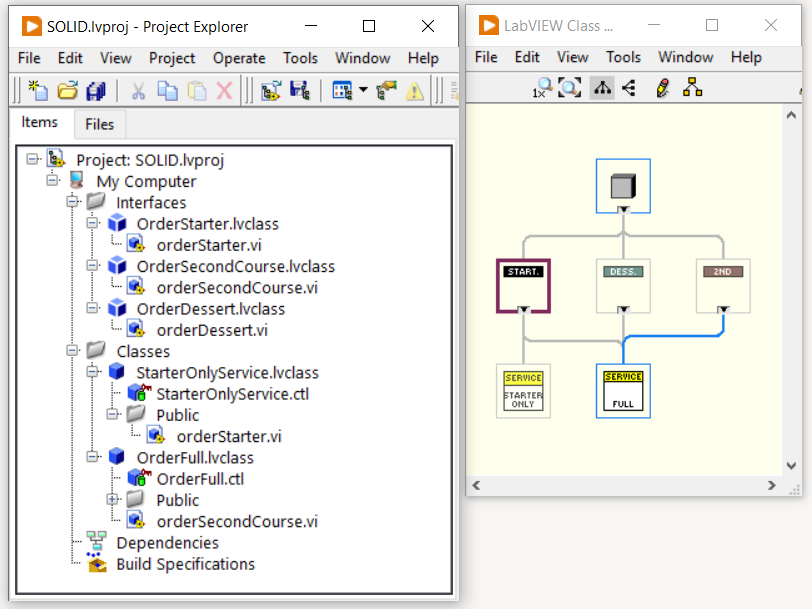
In questo modo, con interfacce piccole e specifiche, abbiamo rispettato il principio di segregazione delle interfacce.
D – Principio di inversione delle dipendenze
Il principio di inversione delle dipendenze (dependency inversion principle) si riferisce al disaccoppiamento dei moduli software. Secondo questo principio, i moduli di alto livello non devono dipendere da quelli di basso livello. Entrambi devono dipendere da astrazioni. Le astrazioni, a loro volta, non devono dipendere dai dettagli ma sono i dettagli a dipendere dalle astrazioni.
Sembra un concetto complicato ma in realtà il succo è che le classi dovrebbero dipendere da interfacce o classi astratte invece che da classi e funzioni concrete. Vediamone un esempio.
Supponiamo di avere un’applicazione per un banco prova che salva i risultati delle prove svolte su un database mySQL. Per fare ciò, creiamo la classe TestReport e la classe mySQLDatabase:
public class TestReport
{
private MySQLDatabase database;
public TestReport(MySQLDatabase db)
{
this.database = db;
}
public void SaveReport()
{
this.database.Save();
}
}
public class MySQLDatabase
{
public void Save()
{
// Save data
}
}
Tutto funziona bene, ma questo codice viola il principio di inversione delle dipendenze perché la nostra classe di alto livello TestReport dipende concretamente dal modulo di basso livello MySQLDatabase. Ciò viola anche il principio aperto-chiuso perché se volessimo un diverso tipo di database o più in generale di persistenza dovremmo mettere mano un po’ a tutte le classi coinvolte.
Per risolvere questo problema e rispettare il principio di inversione delle dipendenze, utilizziamo un’astrazione. Creiamo quindi un’interfaccia Persistency. La classe MySQLDatabase soddisferà questa interfaccia. Allo stesso tempo la classe TestReport dipenderà dall’astrazione Persistency e non più dalla classe concreta MySQLDatabase. Vediamone la nuova struttura:
public class TestReport
{
private Persistency persistency;
public TestReport(Persistency persistency)
{
this.persistency = persistency;
}
public void SaveReport()
{
this.persistency.Save();
}
}
public interface Persistency
{
public void Save();
}
public class MySQLDatabase : Persistency
{
public void Save()
{
Console.WriteLine("Saved in mySQL DB");
}
}
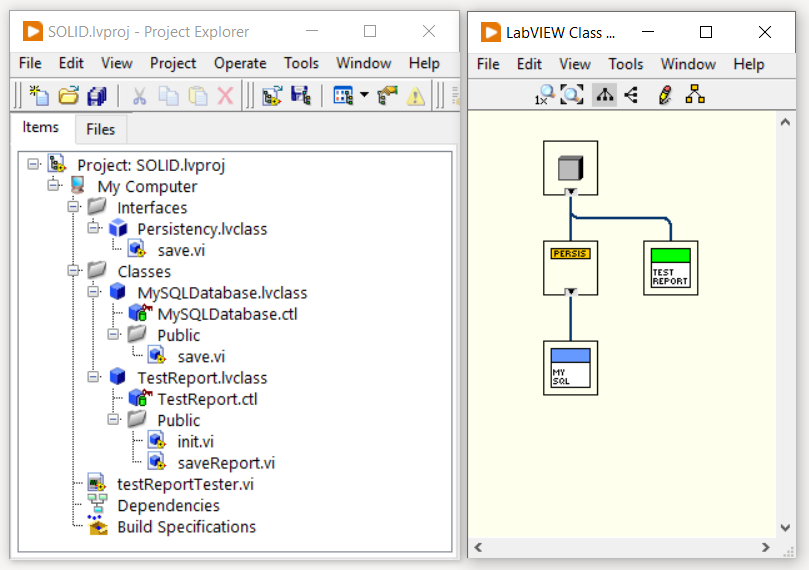
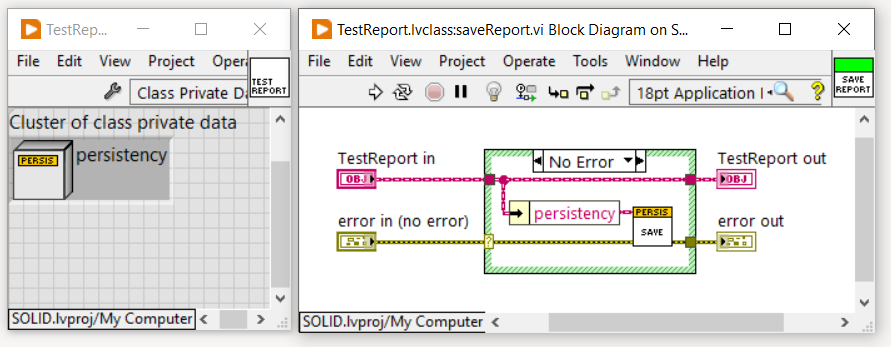
Con questo approccio, grazie all’utilizzo dell’astrazione fornita dall’interfaccia Persistency, non vi è più accoppiamento diretto tra le classi TestReport e MySQLDatabase.
Conclusioni
In questo articolo abbiamo visto i principi di progettazione SOLID. Abbiamo poi visto ogni singolo principio, ognuno con un esempio correlato. Nel limite del buon senso, il mio suggerimento è quello di tenere a mente questi principi durante la progettazione, la scrittura e il refactoring del codice in modo che il codice sia molto più pulito ed estendibile.
Direi che per il momento è tutto. Ringrazio per il tempo dedicato alla lettura di questo articolo e mi auguro che i concetti esposti siano sufficientemente chiari. Nel caso di dubbi, richieste o semplici curiosità, sono disponibile qui.
Al prossimo post.


Hello There. I found your blog using msn. This is a really well written article.
I’ll be sure to bookmark it and return to read more of your useful information. Thanks for the post.
I will definitely comeback.